Знакомство с перебором с возвратами и рекурсией
В текстовом файле crossword.txt задана конфигурация кроссворда в следующем формате:
ШИРИНА ВЫСОТА
X1 Y1 ДЛИНА1 НАПРАВЛЕНИЕ1
X2 Y2 ДЛИНА2 НАПРАВЛЕНИЕ2
...
XN YN ДЛИНАN НАПРАВЛЕНИЕN
Пара координат (Xk, Yk) указывает местонахождение слова (первой буквы) в сетке кроссворда.
Параметр ДЛИНА задает длину слова, а НАПРАВЛЕНИЕ - направление слова.
(v - вертикальное, сверху вниз; h - горизонтальное, слева направо).
Например файл krossword.txt:
13 4
2 0 4 v
0 1 9 h
8 1 3 v
1 3 3 h
7 3 6 h
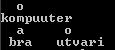
задает кроссворд, изображенный на рис 4.9
Рис 4.9 Пример кроссворда
Второй файл vocabulary.txt содержит словарь, то есть список слов из которых кроссворд будет строиться. Программа должна выдать возможное решение кроссворда используя слова из словаря, либо сообщить, что решения не существует.
Решение
Эта задача хорошо иллюстрирует методику перебора с возвратами. Допустим в кроссворде предусмотрено N позиций, предназначенных для вписывания слов (таким образом решенный кроссворд будут состоять из N слов).
Решение кроссворда сводится к вписыванию некоторого слова в первую свобоную позицию и решению подкроссворда из N-1 позиций. Центральное место в алгоритме решения занимает функция Solve(K), заполняющая подкроссворд начиная с позиции K:
ЦИКЛ по всем незанятым словам словаря
return false
Если теперь вызвать функцию Solve() для самой первой (то есть нулевой) позиции, мы в результате рекурсивной работы функции получим полное решение кроссворда.
Рассмотрим функцию подробнее. Позиция K = N соответствует полностью заполненному кроссворду, поэтому функции остается лишь вернуть значение true (успех).
Если текущая позиция подлежит заполнению, алгоритм просматривает все незанятые слова словаря в поисках подходящего слова. Если очередное слово можно разместить на текущей позиции ( то есть оно подходит по длине и не противоречит уже вписанным буквам), то слово вписывается в кроссворд и вызывает функцию решения подкроссворда, начинающегося с позиции K+1. Если подкроссворд решить не удается (Solve(K+1) возвращает false), алгоритм пытается выбрать другое подходящее слово для вписывания в позицию K.
Займемся теперь реализацией программы. Для начала нам поребуются струтуры, описывающие отдельные буквы, вписываемые в кроссворд, и слова словаря:
//буква со счетчиком
//слово - элемент словаря
struct CharAndCounter{
char Char;
};
int Counter;
CharAndCounter(char _char = ' ', int _counter = 0)
:Char (_char), Counter(_counter){}
struct VocElement{
string String;
};
bool Busy; //флаг "занято/не занято"
VocElement(const string& str = "", bool b = false)
:String(str),Busy(b){}
Зачем букве счетчик? Дело в том, что на уровне псевдокода не видна одна проблема, связанная с операциями "разместить слово" и "снять слово". Предположим, в некоторую позицию кроссворда процедура Solve() решает вписать слово ПОРТ. (рис 4.10).
В итоге эта ветвь перебора заводит в тупик, и теперь алгоритм решения должен снять слово ПОРТ с поля кроссворда. Как видно из рисунка снятие не сводится к простой замене букв П,О,Р,Т пустыми клетками: входящая в состав ранее вписанного слова КРОТ должна быть сохранена.
Решить эту пробелму поможет использование счетчиков. При вписывании очередного слова счетчик, сопоставленный каждой изменяемой клетке, увеличивается на единицу. При снятии слова все соответствующие счетчики уменьшаются на единицу. Если счетчик равен нулю, буква заменяется пробельным символом.
Поле кроссворда представляет собой двумерный массив объектов типа CharAndCounter, а словарь - массив объектов типа VocElement:
vector< vector<CharAndCounter> > Field; // клеточное поле
vector<VocElement> Vocabulary; // словарь
Кроссворд состоит из элементов, описывающих местоположение (первой буквы), направление и длину каждого слова:
//координаты, направление, длина, смещение
WordCoords(int _x, int _y, int _len, char _dir)
int dx() {return (Dir == HORIZONTAL) ? 1 : 0;}
struct WordCoords{
int X, Y;
};
char Dir;
int Length;
:X(_x), Y(_y), Dir(_dir), Length(_len){}
int dy() {return (Dir == VERTICAL) ? 1 : 0;}
Элементы типа WordCoords будем хранить так же в массиве:
vector<WordCoords> Crossword; //координаты слова
Кроме того нам понадобятся следующие переменные:
//глобальные переменные
static const char VERTICAL = 'v', HORIZONTAL = 'h';
int W,H;//высота и ширина поля
Итак мы имеем три структуры и соответственно три вектора для хранения каждой из структур.
Причем для хранения поля из букв используется двумерный вектор Field.
Далее функция ReadData(), при помощи которой все три вектора будут инициализированы
//служебная функция для сортировки слов по длине
//отсортировать словарь по длине слова
//считать описание кроссворда
for(;;){ //заполнить все поле пустыми символами
(заполнены данными).
bool Less(const VocElement& lhs, const VocElement& rhs){
return lhs.String.length() < rhs.String.length();
}
void ReadData(){
ifstream crossw("crossword.txt"), voc("vocabulary.txt");
}
string temp;
//считать последовательно все слова словаря
while(!voc.eof()){
voc >> temp;
}
Vocabulary.push_back(VocElement(temp, false));
sort(Vocabulary.begin(), Vocabulary.end(), Less);
int x,y,len;
char dir;
//ширина и высота поля
crossw >> W; crossw >> H;
//считать очередной элемент описания
}
crossw >> x; crossw >> y;
crossw >> len; crossw >> dir;
if(crossw.eof())
break;
Crossword.push_back(WordCoords(x,y,len,dir));
for(int i = 0; i < W; i++){
vector}
CharAndCounter _one(' ',0);//экземпляр структуры
fill(col.begin(), col.end(), _one);//заполняем вектор данными
Field.push_back(col);//помещаем вектор в вектор
Сортировка словаря по длине слов поможет в дальнейшем ускорить работу программы. Впрочем об этом позже, а сейчас рассмотрим три важные функции:
//------------------------
bool CanPlace(WordCoords c, const string& word){
for(unsigned i = 0; i < word.length(); i++){}
if(Field[c.X + i*c.dx()][c.Y + i*c.dy()].Char != ' ' &&
}
Field[c.X + i*c.dx()][c.Y + i*c.dy()].Char != word[i])
return false;
return true;
//----------------------
void PlaceWord(WordCoords c, const string& word){
for(unsigned i = 0; i < word.length(); i++){}
Field[c.X + i*c.dx()][c.Y + i*c.dy()].Char = word[i];
}
Field[c.X + i*c.dx()][c.Y + i*c.dy()].Counter++;
//-------------------------
void RemoveWord(WordCoords c, const string& word){
for(unsigned i = 0; i < word.length(); i++){}
if(--(Field[c.X + i*c.dx()][c.Y + i*c.dy()].Counter) == 0)
}
Field[c.X + i*c.dx()][c.Y + i*c.dy()].Char = ' ';
Эти функции определяют:
1. Можно ли разместить слово word на позиции c?
(предполагается, что длина слова нас устраивает, требуется определить соответствие букв слова - уже имеющимся на поле буквам).
2. Разместить слово word в позиции c (предполагается, что это возможно)
3. Снять слово word с позиции c
Основная функция решения Solve() соответствует псевдокоду, приведенному выше:
bool Solve(unsigned CoordNo){
if(CoordNo == Crossword.size())
return true;
//получить диапазон слов, длина каждого из которых
//равна Crossword[CoordNo].Length
pair<vector<VocElement>::iterator, vector<VocElement>::iterator> range =
equal_range(Vocabulary.begin(), Vocabulary.end(),
string(Crossword[CoordNo].Length, ' '),Less);
//цикл по словам словаря
for(vector::iterator p = range.first;p != range.second;p++){
if(!p->Busy && CanPlace(Crossword[CoordNo], p->String)){
//если слово не занято
//и его можно разместить на позиции Crossword[CoordNo]
PlaceWord(Crossword[CoordNo], p->String);// разместить слово
p->Busy = true;//теперь слово занято
if(Solve(CoordNo + 1))
return true;
RemoveWord(Crossword[CoordNo], p->String);
p->Busy = false;
} //end if
}//end for
return false;
}
Как указано в псевдокоде, алгоритм Solve() перебирает все незанятые слова словаря.
Для ускорения работы программы я внес небольшое улучшение, зачем перебирать все слова, если заведомо известно, что лишь слова длины Crossword[CoordNo].Length могут быть успешно размещены в позиции Crossword[CoordNo] кроссворда?
С помощью функции equal_range() из отсортированного словаря можно "за одни присест"
извлечь поддиапазон слов, длины которых равны Crossword[CoordNo].Length.
Поскольку определенная выше функция Less() сравнивает длины слов, в качестве третьего
аргумента equal_range() может использоваться любая строка требуемой длины, например,
строка, заполненная Crossword[CoordNo].Length пробелами.
(АВ: то есть здесь строка длины Crossword[CoordNo].Length, заполненная пробелами).
Для того, чтобы лучше разобраться в работе этой функции
bool Solve(unsigned CoordNo){
for(vector
упростим ее
if(CoordNo == Crossword.size())
}
return true;
//получить диапазон слов, длина каждого из которых
//равна Crossword[CoordNo].Length
pair<vector<VocElement>::iterator, vector<VocElement>::iterator> range =
equal_range(Vocabulary.begin(), Vocabulary.end(),
string(Crossword[CoordNo].Length, ' '),Less);
cout << p->String << " " << endl;
}
return false;
Вывод: omar krot
Анализ:
При первом вызове функции Solve() в главной программе ей передается аргумент 0.
То есть вызывается первый элемент вектора Crossword. А значение переменной Length
в первой структуре вектора равно 4. Поэтому выводится поддиапазон слов из четырех символов.
Осталось лишь запрограммировать простую функцию main():
if(Solve(0)){
return 0;
int main(int args,char* argv[]){
ReadData();
}
for(unsigned y = 0; y < Field[0].size(); y++){}
for(unsigned x = 0; x < Field.size(); x++){}
cout << Field[x][y].Char;
}
cout << endl;
else{
cout << "not solushion" << endl;
}
Результат:
Пример входных данных
Содержимое файла crossword.txt
13 4
2 0 4 v
0 1 9 h
8 1 3 v
1 3 3 h
7 3 6 h
Содержимое файла vocabulary.txt
компьютер
омар
бра
рот
утварь
крот
сервер
аромат
радио
В результате работы программы получится следующий кроссворд:
Назад |
Начало урока |
Вверх |
Вперед
Содержание